

A simple, yet common, problem for MDX reports is combining non-measure members which are query specific. The requirement to combine the members is a reporting requirement which means it doesn't belong in the cube. Here's hte problem statement and two solutions.
I want to select not only [Aus - New South Wales], but also [Canada - Alberta], and show both as one sum, not 2 separate columns. Normally, the WHERE clause needs a tuple, and each dimension can only appear once in a tuple. The following MDX illustrates the use of a single reference to the customer dimension in the WHERE clause.
SELECT
NON EMPTY {Measures.[Internet Sales Amount], Measures.[Internet Tax Amount]} ON COLUMNS,
NON EMPTY {[Product].[Product Categories].[Category].ALLMEMBERS} ON ROWS
FROM [Adventure Works]
WHERE ([Date].[Calendar].[Calendar Year].&[2004],[Customer].[Customer Geography].[State-Province].&[NSW]&[AU])
One solution is creating a calculated member which SUM()s the values for NSW and Alberta, but the trick is placing the new calculated memebr as part of the Customer dimension which makes it independent of the Measure selected. Most MDX beginners assume you can only create new Measures. That's not the case. A Calculated member can belong in any Dimension.Hierarchy. Here's the solution with the calculated member which is then referneced in the WHERE clause to slice by the SUM() of the two country members.
WITH
MEMBER [Customer].[Customer Geography].[Test SUM] AS
'
SUM({[Customer].[Customer Geography].[State-Province].&[NSW]&[AU], [Customer].[Customer Geography].[State-Province].&[AB]&[CA]}, Measures.CurrentMember)
'
SELECT
NON EMPTY {Measures.[Internet Sales Amount], Measures.[Internet Tax Amount]} ON COLUMNS,
NON EMPTY {[Product].[Product Categories].[Category].ALLMEMBERS} ON ROWS
FROM [Adventure Works]
WHERE ([Date].[Calendar].[Calendar Year].&[2004],[Customer].[Customer Geography].[Test SUM])
Another solution (thanks to Deepak Puri) is using a SET reference in the WHERE clause which combines the two members as a set, and CROSSJOINs the set with the other members in the WHERE clause. This a nice trick, and not obvious - even to experienced MDX coders.
SELECT
NON EMPTY {Measures.[Internet Sales Amount], Measures.[Internet Tax Amount]} ON COLUMNS,
NON EMPTY {[Product].[Product Categories].[Category].ALLMEMBERS} ON ROWS
FROM [Adventure Works]
WHERE CROSSJOIN({[Customer].[Customer Geography].[State-Province].&[NSW]&[AU], [Customer].[Customer Geography].[State-Province].&[AB]&[CA]}, {[Date].[Calendar].[Calendar Year].&[2004]})
12 October 2006
13 September 2006
Percent Contribution for ALL Hierarchies
I ran across an interesting question from the MSDN forum which challenged my MDX ability making it worth sharing. The question posed on the forum was, "The user requirement is ability to get cross tabulations among the dimensions. For example, they may want the proportion of cases in each year at a given location or the proportion of cases in each year by product? In this case, I'd need a generalized contribution precentage formula because I'll never be sure which dimension(s) users may cross-tab."
This type of "generic" contribution precentage calculation is useful for reports where a users experience is "guided", however, I'd caution against using this type of percentage calculation for ad-hoc users because they'll likely end up with slices of the data which affect percentages displayed not realizing all the slices in effect.
The tricks to this calculated member are: (1) Avoid division by zero error, and (2) Use the.DefaultMember when the .CurrentMember is the highest member in the hierarchy.
Trick (1) is taken care of in the IIF() statement which returns NULL if ANY (.CurrentMember, Measure) tuple returns empty. Trick (2) is handled in the denominator of the percentage calculation by detecting the .CurrentMember level and using DefaultMember when appropriate.
WITH MEMBER Measures.[Percent Customer Count] AS
'
IIF(ISEMPTY([Measures].[Customer Count]), NULL,
IIF([Product].[Product Categories].CurrentMember.Level.Ordinal <> 0 AND
ISEMPTY(([Product].[Product Categories].CurrentMember.Parent, Measures.[Customer Count])), NULL,
IIF([Date].[Calendar].CurrentMember.Level.Ordinal <> 0 AND
ISEMPTY(([Date].[Calendar].CurrentMember.Parent, Measures.[Customer Count])), NULL,
IIF([Customer].[Customer Geography].CurrentMember.Level.Ordinal <> 0 AND
ISEMPTY(([Customer].[Customer Geography].CurrentMember.Parent, Measures.[Customer Count])), NULL,
// Do the calculation
([Product].[Product Categories].CurrentMember
,[Date].[Calendar].CurrentMember
,[Customer].[Customer Geography].CurrentMember
,[Measures].[Customer Count])
/
(IIF([Product].[Product Categories].CurrentMember.Level.Ordinal = 0, [Product].[Product Categories].DefaultMember, [Product].[Product Categories].CurrentMember.Parent)
,IIF([Date].[Calendar].CurrentMember.Level.Ordinal = 0, [Date].[Calendar].DefaultMember, [Date].[Calendar].CurrentMember.Parent)
,IIF([Customer].[Customer Geography].CurrentMember.Level.Ordinal = 0, [Customer].[Customer Geography].DefaultMember, [Customer].[Customer Geography].CurrentMember.Parent)
,[Measures].[Customer Count])
)
)
)
)
' ,SOLVE_ORDER=10, FORMAT_STRING="#,0.0%"
SELECT
{[Measures].[Customer Count], Measures.[Percent Customer Count]} ON COLUMNS
,{[Product].[Product Categories].[All]
,DESCENDANTS([Product].[Product Categories].[All], [Product].[Product Categories].[Category])} ON ROWS
FROM [Adventure Works]
WHERE(
[Date].[Calendar].[Calendar Year].&[2003]
,[Customer].[Customer Geography].[Country].&[United States]
)
The above example works with the AdventureWorks DW database, but only on three of the hierarchies. Which implies the biggest drawback of this implementation technique - if you have more than 5-6 hierarchies the nesting of the IIF() and maintenance of the MDX is tedious and error prone. However, if you're diligent it will work.
This type of "generic" contribution precentage calculation is useful for reports where a users experience is "guided", however, I'd caution against using this type of percentage calculation for ad-hoc users because they'll likely end up with slices of the data which affect percentages displayed not realizing all the slices in effect.
The tricks to this calculated member are: (1) Avoid division by zero error, and (2) Use the
Trick (1) is taken care of in the IIF() statement which returns NULL if ANY (
WITH MEMBER Measures.[Percent Customer Count] AS
'
IIF(ISEMPTY([Measures].[Customer Count]), NULL,
IIF([Product].[Product Categories].CurrentMember.Level.Ordinal <> 0 AND
ISEMPTY(([Product].[Product Categories].CurrentMember.Parent, Measures.[Customer Count])), NULL,
IIF([Date].[Calendar].CurrentMember.Level.Ordinal <> 0 AND
ISEMPTY(([Date].[Calendar].CurrentMember.Parent, Measures.[Customer Count])), NULL,
IIF([Customer].[Customer Geography].CurrentMember.Level.Ordinal <> 0 AND
ISEMPTY(([Customer].[Customer Geography].CurrentMember.Parent, Measures.[Customer Count])), NULL,
// Do the calculation
([Product].[Product Categories].CurrentMember
,[Date].[Calendar].CurrentMember
,[Customer].[Customer Geography].CurrentMember
,[Measures].[Customer Count])
/
(IIF([Product].[Product Categories].CurrentMember.Level.Ordinal = 0, [Product].[Product Categories].DefaultMember, [Product].[Product Categories].CurrentMember.Parent)
,IIF([Date].[Calendar].CurrentMember.Level.Ordinal = 0, [Date].[Calendar].DefaultMember, [Date].[Calendar].CurrentMember.Parent)
,IIF([Customer].[Customer Geography].CurrentMember.Level.Ordinal = 0, [Customer].[Customer Geography].DefaultMember, [Customer].[Customer Geography].CurrentMember.Parent)
,[Measures].[Customer Count])
)
)
)
)
' ,SOLVE_ORDER=10, FORMAT_STRING="#,0.0%"
SELECT
{[Measures].[Customer Count], Measures.[Percent Customer Count]} ON COLUMNS
,{[Product].[Product Categories].[All]
,DESCENDANTS([Product].[Product Categories].[All], [Product].[Product Categories].[Category])} ON ROWS
FROM [Adventure Works]
WHERE(
[Date].[Calendar].[Calendar Year].&[2003]
,[Customer].[Customer Geography].[Country].&[United States]
)
The above example works with the AdventureWorks DW database, but only on three of the hierarchies. Which implies the biggest drawback of this implementation technique - if you have more than 5-6 hierarchies the nesting of the IIF() and maintenance of the MDX is tedious and error prone. However, if you're diligent it will work.
07 September 2006
Officially - I'm a Nerd (though barely)
OK - I took the test. Nerd score of 59. Not much. Looks like I need some work.
What's your nerd score?

What's your nerd score?
01 September 2006
Cube Collation causes ERROR in Excel Addin
I ran across an interesting error earlier this week using the Cube Analysis add-in of Excel. I set up a connection using Cube Analysis (Cube Analysis Manage Connection), then proceeded to create a report (Cube Analysis Build Report). When I selected the Data View pane and selcted a dimension/hierarchy the pane which shows the hierarchy with members showed -ERROR.
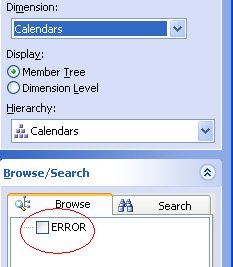
Through a trial and error process of comparing an Adventure Works cube to the cube which caused the error I discovered there was an difference in the collation sequence of the cube (cube property exposed in BI Studio). The Adventure Works cube had collation setting "Latin1 General, Accent sensitive". The cube which threw the error had collation setting "Latin1 General, Case sensitive, Accent sensitive". Changing the collation of the cube to "Latin1 General, Accent sensitive" eliminated the error.
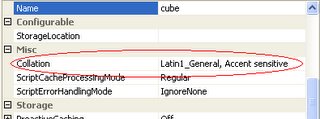
My conclusion is that the Case sensitive setting in the cube collation forced the Cube Analysis Excel add-in to throw the error.

Through a trial and error process of comparing an Adventure Works cube to the cube which caused the error I discovered there was an difference in the collation sequence of the cube (cube property exposed in BI Studio). The Adventure Works cube had collation setting "Latin1 General, Accent sensitive". The cube which threw the error had collation setting "Latin1 General, Case sensitive, Accent sensitive". Changing the collation of the cube to "Latin1 General, Accent sensitive" eliminated the error.
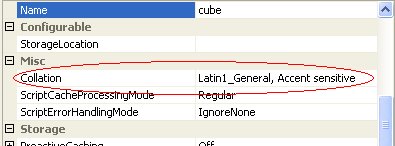
My conclusion is that the Case sensitive setting in the cube collation forced the Cube Analysis Excel add-in to throw the error.
31 August 2006
Begin Count and End Count with MDX Effective Recursion
Problem:
A consulting company tracks their consultant headcount with Hires, Terminations and Transfers. Their consultant “inventory” is derived into [Begin Count] and [End Count]. Nearly all other metrics rely upon the beginning and ending headcounts for such things as FTE utilization, average cost per FTE, etc. A consulting company really has no other capital assets making headcount very important.
The problem stems from the calculations where [End Count] relies on [Begin Count]. We’d like calculations which are easy to maintain and get good query performance for reports and ad-hoc quiries.
Implementation Platform:
Cube based calculated members in SQL Server Analysis Services 2005.
Business Definitions:
[End Count] = [Begin Count] + [Termination Count] + [Hire Count] + [Transfer Count]
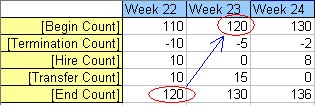
[Begin Count] = [End Count] of the prior period. Example: [End Count] for Week 22 is 120 which becomes the [Begin Count] for Week 23.
A consulting company tracks their consultant headcount with Hires, Terminations and Transfers. Their consultant “inventory” is derived into [Begin Count] and [End Count]. Nearly all other metrics rely upon the beginning and ending headcounts for such things as FTE utilization, average cost per FTE, etc. A consulting company really has no other capital assets making headcount very important.
The problem stems from the calculations where [End Count] relies on [Begin Count]. We’d like calculations which are easy to maintain and get good query performance for reports and ad-hoc quiries.
Implementation Platform:
Cube based calculated members in SQL Server Analysis Services 2005.
Business Definitions:
[End Count] = [Begin Count] + [Termination Count] + [Hire Count] + [Transfer Count]
[Begin Count] = [End Count] of the prior period. Example: [End Count] for Week 22 is 120 which becomes the [Begin Count] for Week 23.
[Termination Count], [Hire Count], and [Transfer Count] are loaded measures.
Solution #1:
An elegant solution is available by taking advantage of the .PrevMember function in MDX.
We define [Begin Count] as:
MEMBER Measures.[Begin Count] AS
'
([Calendars].[Calendars].CurrentMember.PrevMember, Measures.[End Count])
'
From our example above Week 24 [Begin Count] is the [End Count] for Week 23 which is the value 130. Week 23 [Begin Count] is the [End Count] for Week 22 which is the value 120. If we had more data history the same pattern is followed.
We define [End Count] as:
MEMBER Measures.[End Count] AS
'
Measures.[Begin Count]
+ [Measures].[Hire Count]
+ [Measures].[Termination Count]
+ [Measures].[Transfer Count]'
Referencing [Begin Count] within the addition executed of [End Count] introduces a recursive definition where every [End Count] calculation uses [Begin Count] which in turn references [End Count].
For those familiar with recursive solutions (such as the Tower of Hanoi) you should recognize there is no “end point” to end the recursion. Recursive solutions typically have a check which tells the recursion to quit and return. As an example here is pseudo-code for a recursive function:
Function SolveIt( N, Src, Aux, Dst)
Begin
If N = 0 Then Exit Function
Else
Begin
SolveIt(N-1, Src, Dst, Aux)
Move from Src to Dest
SolveIt(N-1, Aux, Src, Dst)
End
End
The line “If N = 0 Then Exit Function” is our exit criteria for the recursion.
Our definition of [Begin Count] does not contain exit criteria for the recursion. Instead of an explicit exit criteria we rely upon an implied recursion end point from Analysis Services. The implied recursion end point comes from using:
[Calendars].[Calendars].CurrentMember.PrevMember
Eventually .PrevMember will reference a date outside the cube space. When the reference occurs the tuple ([Calendars].[Calendars].CurrentMember.PrevMember, Measures.[End Count]) returns NULL ending the recursion.
As an example we have a very limited calendar dimension with only 5 consecutive weeks. The data shown is for a division of the company which started in Week 20 by transferring 100 employees into the division and hiring 5 new employees.
The Week 20 [Begin Count] is null because it references .PrevMember which doesn’t exist. If we intercepted the [Begin Count] definition while Week 20 is the CurrentMember the tuple would look like this:
([Calendars].[Calendars].[Week 20].PrevMember, Measures.[End Count])
There is no previous member for Week 20 which results in a null value for the tuple form Analysis Services.
A problem arises with Solution #1 when we have a even a small number of members to recurse through which resolves [Begin Count]. Performance of [Begin Count] can get very slow. As an example a Calendar dimension with 12 years with a hierarchy of Year-Quarter-Month-Day has 4380 day level members (365 * 12). The above solution can take up to 30 minutes to return (on a 2 processor 2GB dev server) when getting Calendar.CurrentMember is a day member. We can improve performance by modifying the above calculated members. The modification is described below in Solution #2.
Solution #2:
This solution is an expansion of Solution #1 modified to take advantage of the non-additive nature of [Begin Count]. Solution #2 relies upon the [Begin Count] quality where [Begin Count] is the same value for the first member in a period regardless of which level the member belongs to in the Calendar hierarchy. For example, if [Begin Count] is 150 for the year 2006, the [Begin Count] is the same value (150) for Q1-2006, and the same for Jan-2006, and the same for 1 Jan 2006.
Calendar Member [Begin Count]
------------------ --------------
2006 150
Q1-2006 150
Jan 2006 150
1 Jan 2006 150
Solution #2 exploits the quality where the Parent of a member has the same [Begin Count] value as the member if the member is the first sibling of the parent.The following MDX is used in Solution#2.
MEMBER Measures.[New End Count] AS
'
IIF([Calendars].[Calendars].CurrentMember.Parent.Properties("KEY") = "3" // At the [Calendars].[Calendars].[Calendar Group].&[Fiscal] so go to first year.
, // TRUE
([Calendars].[Calendars].[Calendar Group].&[Fiscal].FirstChild ,[Measures].[Hire Count])
+ ([Calendars].[Calendars].[Calendar Group].&[Fiscal].FirstChild, [Measures].[Termination Count])
+ ([Calendars].[Calendars].[Calendar Group].&[Fiscal].FirstChild, [Measures].[Transfer Count])
, // FALSE
Measures.[New Begin Count]
+ [Measures].[Hire Count]
+ [Measures].[Termination Count]
+ [Measures].[Transfer Count]
)
'
[End Count] is an IIF() which is described in the following pseudo-code:
Function [End Count]
IF Calendar.CurrentMember.Parent is the highest valid point in the hierarchy THEN
Add up the Hire, Termination, and Transfer counts related to
the [Fiscal] member as [End Count].
This is the end point of our recursion.
ELSE
Add up Begin, Termination, Hire, and Transfer count as [End Count].
The reference to [Begin Count] force us to recurse back to the
[Begin Count] definition.
ENDIF
MEMBER Measures.[New Begin Count] AS
'
IIF([Calendars].[Calendars].CurrentMember.FirstSibling.Properties("ID") =
[Calendars].[Calendars].CurrentMember.Properties("ID")
, // TRUE
([Calendars].[Calendars].CurrentMember.Parent, Measures.[New Begin Count])
, // FALSE
([Calendars].[Calendars].CurrentMember.PrevMember, Measures.[New End Count])
)
'
The IIF() statement in [Begin Count] is best described with the following pseudo-code:
Function [Begin Count]
IF Calendar.CurrentMember is the first sibling THEN
Use [Begin Count] with Calendar.CurrentMember.Parent
ELSE
Use [End Count] with Calendar.CurrentMember.PrevMember
ENDIF
Using the technique where we look for the parents of first siblings allows the evaluation of [Begin Count] with far fewer recursive calls than if we use the recursive technique in Solution #1. The reduction in the number of recursive calls is what makes Solution #2 execute at an acceptable speed.
The first post to my new blog. Very exciting. The primary intent, and motivation to start, this blog was the intermittent success I've had searching for answers to the many MS Analysis Services 2005 issues I run across. MS Anlaysis Services 2005 is growing in popularity as the implementation tool for data analysis and the focus here is on practical solutions I've found for common business problems. Special attention is given to MDX (multi dimensional expressions) solutions and explanations. I hope that others will benefit from postings and I'll get some hints in return.
Subscribe to:
Posts (Atom)